
What is the problem here?
At Luos, we deal with distributed (multi-MCU) critical and real-time environments. Everything in our technology has been thought to be fast and lightweight. The Robus protocol (our basic protocol) has been designed to have the minimal latency possible, but we still have some!
For now, our users ignore this latency and consider it null. It is good enough for most applications because latency added by Luos engine rarely exceeds a few milliseconds. But Luos engine can't just guarantee this low latency in any configuration.
For example, if there are many collisions in a system, a message could be delayed multiple times, dramatically unpredictably increasing the latency. And worse than that, in this kind of situation, we can have younger data arriving before the oldest one, thus compromising the system's determinism.
Luos have to provide tools allowing users to deal with this latency in a critical real-time environment.
⚠️ What do we consider a latency: In a critical real-time system, the latency we have to consider is the time between the actual data generation and the moment it is consumed. In this latency measurement, the network latency is included and any treatment and wires propagation time.
How do people deal with it today?
In such an architecture, it is physically impossible to remove latency. At best, we can reduce it but never remove it. So to deal with this latency, we have to be able to measure it and take care of dates values when we use it.
Luos engine needs to timestamp data to be deterministic and complex real-time compliant.
Timestamp = Timeline
If we want a timestamp, we have to maintain a timeline. But maintaining a timeline in a distributed architecture is not as simple as it seems because we have different MCU, started at other times, cadenced at a different frequency, with different temperatures adding various drifting.
Any node has own timeline, so we have multiple concurrent timelines in the entire system, exchanging data that has to be timestamped.
Timeline synchronization is a common way.
People synchronize timelines to have a coherent timestamp of data across different nodes. They have to designate an initiator system that will synchronize the dates in all the nodes to do it. This operation is achieved by sending specific messages and frequently updating them to avoid drifting and keep them synchronized. To operate with precision, this clear synchronization message needs a predictable latency guaranteeing the accuracy of the date. To do so, we generally need to stop every operation in the network to ensure that the latency will always be the same.
What are the problems we have with it?
This common date synchronization is not relevant for Luos engine because it follows initiator-follower management, which we don’t have in Luos architectures. The closest to an initiator system we have is the node performing detection.
One of the rules we have in the Luos philosophy is "Don't do something if the user doesn't do it voluntarily.".
Following this rule, automatically sending messages behind the back of the user and locking communications to manage any Luos operation is not acceptable.
Also, to keep it nanosecond-precise across different MCUs and boards, we will have to re-synchronize dates frequently.
Just presuming the latency during this synchronization phase also seems ambitious because of those differences, and we don’t masters the latency of users’ physical drivers or the protocol they use.
To make it more precise, we should be able to measure the actual latency. <== This will lead me to the Luos way...
The Luos way to make it.
As we previously saw, trying to have only one typical timeline for every node is not adapted to the Luos philosophy.
During the first part of this article, we talked about latency. We need to have a good latency evaluation to have a good time precision. The best way to do it is to be able to measure it for real.
And if we can measure it, why maintain a typical timeline? We can use this latency value to know the real local date of an event: no more global timeline, just a delta between data generation and consumption.
If we only measure latency without maintaining a timeline, can we still have real-time behavior?
Yes, absolutely.
Of course, real-time developers are used to working with a global timeline, but based on latency, we can easily rebase the event into the node’s local timeline. That is what we will do.
$eventDate = currentDate - latency$
Doesn't it confuse us to understand what is going on into the product?
Absolutely not.
Of course, in a distributed product, any node will own different timelines, which will look like a big mess. But as a user, you are looking at it from one point on the system (a Gate, an Inspector, or your app service). So the reference timeline from your point of view will be the local timeline of the node you are looking through. Nobody will notice that there are multiple timelines.
Is it precise?
Yes, absolutely.
It is exactly like if we are re-synchronizing all the timelines at each data exchange, so we can almost ignore the time drifting here.
Why isn’t nobody doing it this way?
I don't know.
I talked with Edward Lee from the University of Berkeley and learned they wrote a paper about these subjects. They are the only ones I know that work on this, and they don't do it for embedded systems (for now).
[PDF] A Programming Model for Time-Synchronized Distributed Real-Time Systems | Semantic ScholarIf you hear of anyone working there the way we do in Luos, let me know.
How to compute latency?
Computing the latency in such a configuration is a shared work across the nodes.
Basically, the latency is a sum of delays:
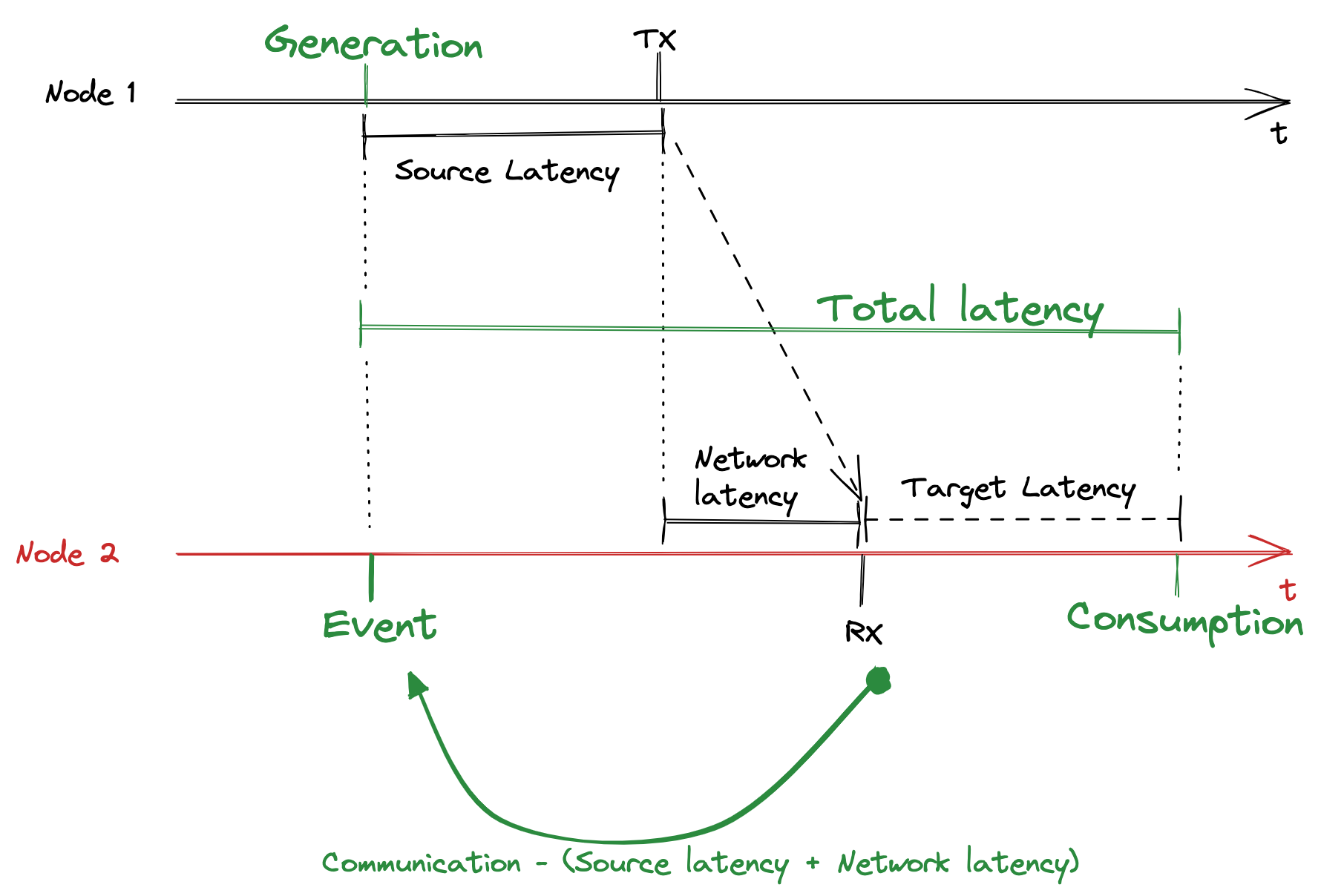
sourceLatency = communicationDate - dataGenerationDate
targetLatency = dataConsumingDate - communicationDate
networkLatency = propagationTime + IRQraise
totalLatency = sourceLatency + targetLatency + networkLatency
The reference event for latency computation
We need to have a common measurable event across the nodes to compute the latency. This event has to come from the network shared by all the nodes.
When we start receiving or transmitting a message, we have to keep this event’s date to be able to compute latency. The communicationDate is taken by all the nodes in the reception IRQ of the first message’s byte.
This event still has a small latency represented by the propagation timeline and the local IRQ raising time. You can still experimentally measure this latency and add it as an offset in your calculation.
Source latency
The source latency is the delay between data generation and the communicationDate event. After collision detection, we are sure to transmit the entire message, and we can compute this delta and add it after the header of the current transmitting message.
Target latency
The target latency is the delay between the communicationDate event and data consumption. But because we want to put it as soon as possible into a local timeline.
To place the dataGenerationDate in local timeline, we can do as following:
dataGenerationDate = communicationDate - (sourceLatency + networkLatency)
Event vs. Generation
The real information we want to get is the date of the Event. When you evaluate a sensor measurement event, the Generation date and the actual Event are the same. But you could also need to have an event in the past or the future, for example, in the case of a motor’s movement. So the Generation date and the actual Event are not always the same.
That is why we have to take care of the Event’s date, not specifically of the data Generation’s date.
To know if the event is in the past or the future, we need Delta to be a signed value.
An example of an event in the past:
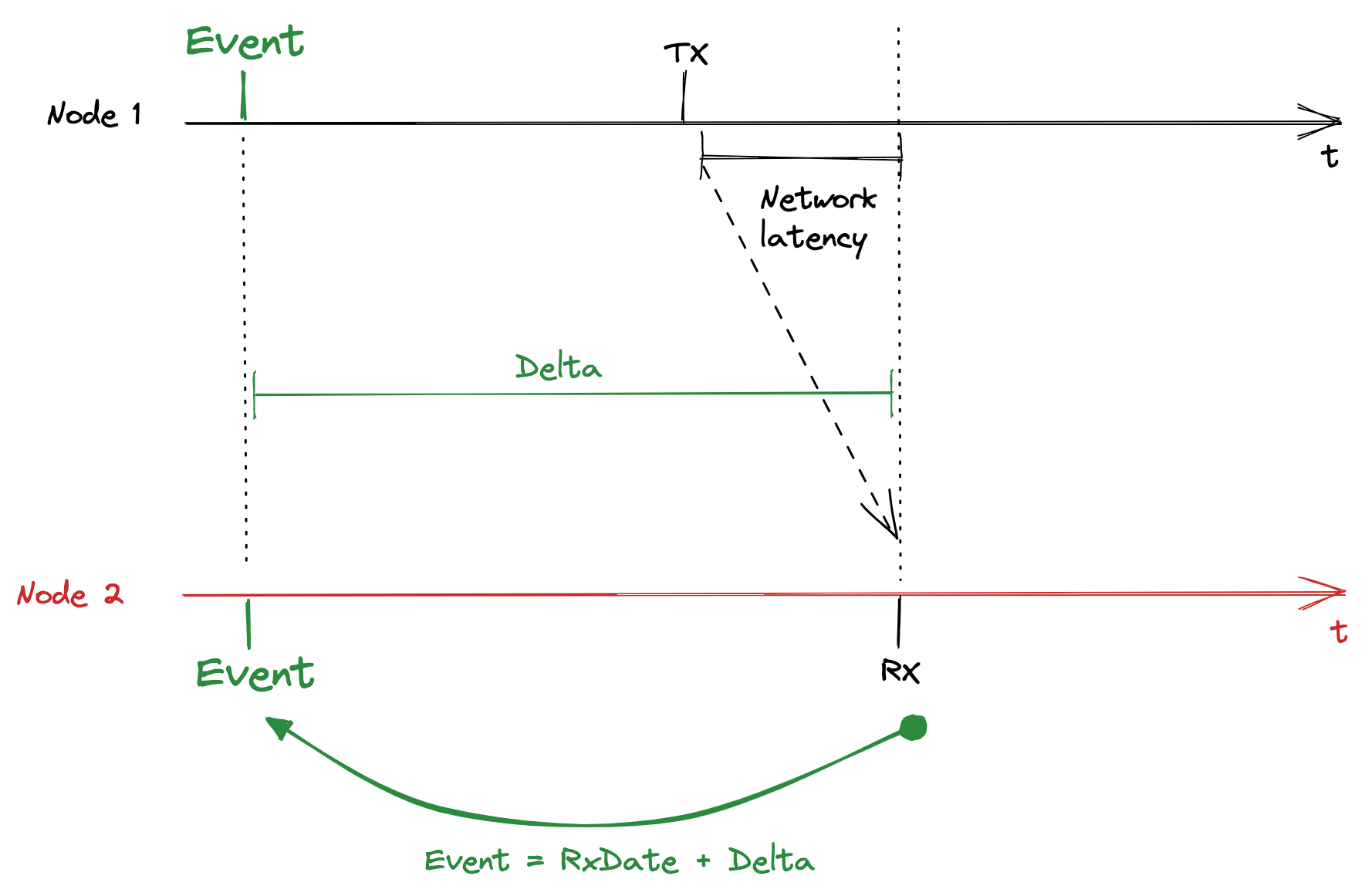
At the TX communication’s date, we compute the signed Delta value and send it:
Delta = EventDate - (TxDate + NetworkLatency)
In this case, Delta will be negative.
At the RX Communication’s date, we just have to do:
EventDate = RxDate + Delta
An example of an event in the future:
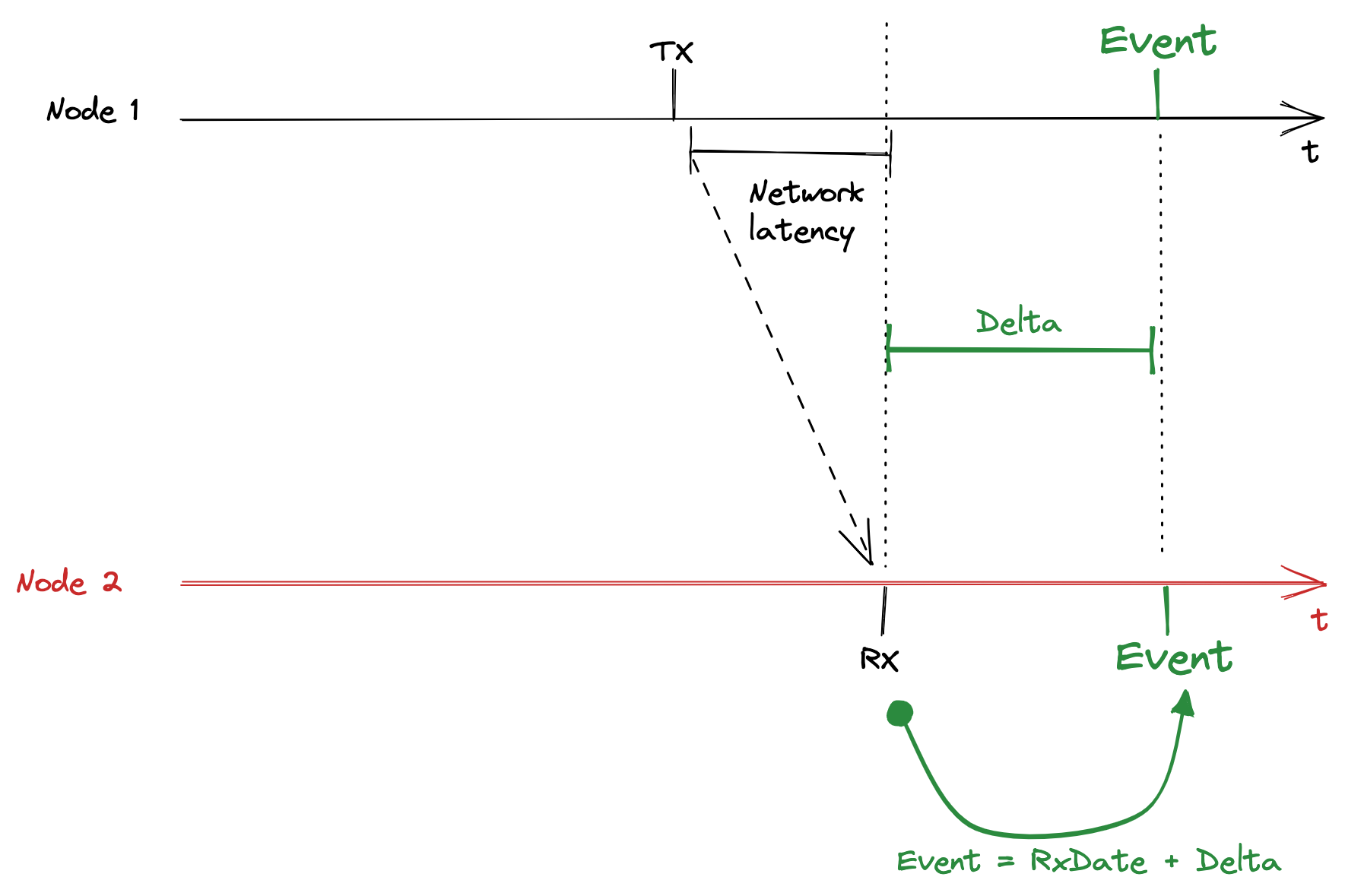
In this case, Delta will be positive.
Get Started with Luos